AI pipeline for PVA record extraction
Challenge
Our client conducts PVA (Property Valuation Administrator) research across Kentucky—covering every county in the state. Each year their team examines between 5,000 and 10,000 records, a volume that forces hard tradeoffs: with that many documents to get through, reviewers could only rely on a handful of data points per record when making assessment decisions.
The records themselves were no easier. Critical valuation and property data lived in inconsistent formats—scanned PDFs, legacy exports, and mixed layouts. Manual review was slow, error-prone, and could not scale to capture everything in each file. The team needed to keep the same annual throughput while actually seeing the full picture on every record, not just the few fields they had time to skim.
Solution
We designed and built a new AI pipeline processing service tailored to their statewide workflow:
- Ingest — Batch upload and queue thousands of records with validation at the point of entry. New work can land every day instead of waiting for ad-hoc batch cycles.
- Process — Model-assisted extraction pulls structured fields from the entire record, not just the few attributes reviewers used to prioritize by hand. Confidence scoring flags uncertain results.
- Review — Low-confidence extractions route to a human review queue instead of silently failing, so quality stays high at volume.
- Summarize — AI-generated summaries roll up record-level detail so analysts can scan trends and outliers without re-reading every source document.
- Deliver — Clean, uniform structured output feeds directly into the client’s existing systems via API and export—the same shape whether the source was a scan, a PDF, or a legacy export.
The service runs as a repeatable pipeline: records drop in, process automatically, and results are ready without rebuilding the workflow each time. The team can still examine roughly the same number of records per year, but the system does the heavy lifting of reading and normalizing everything while people focus on judgment and decisions.
Results
- ~500% faster end-to-end data collection compared to manual extraction at the same record volume
- ~20× more data available per record for analysis and decisions (we estimate roughly 2,000% more usable fields and context than the prior “few fields only” approach)
- 5,000–10,000 records per year processed through a single, repeatable pipeline across all Kentucky counties
- Daily structured output in a uniform schema, plus AI summaries for quicker review
- Dramatically reduced manual data entry; reviewers spend time on decisions, not retyping
- Established a repeatable process for ongoing record batches and year-over-year research
The PVA record for a property is represented in a single sentence. Here is a sample image for a house built in the 1800s.
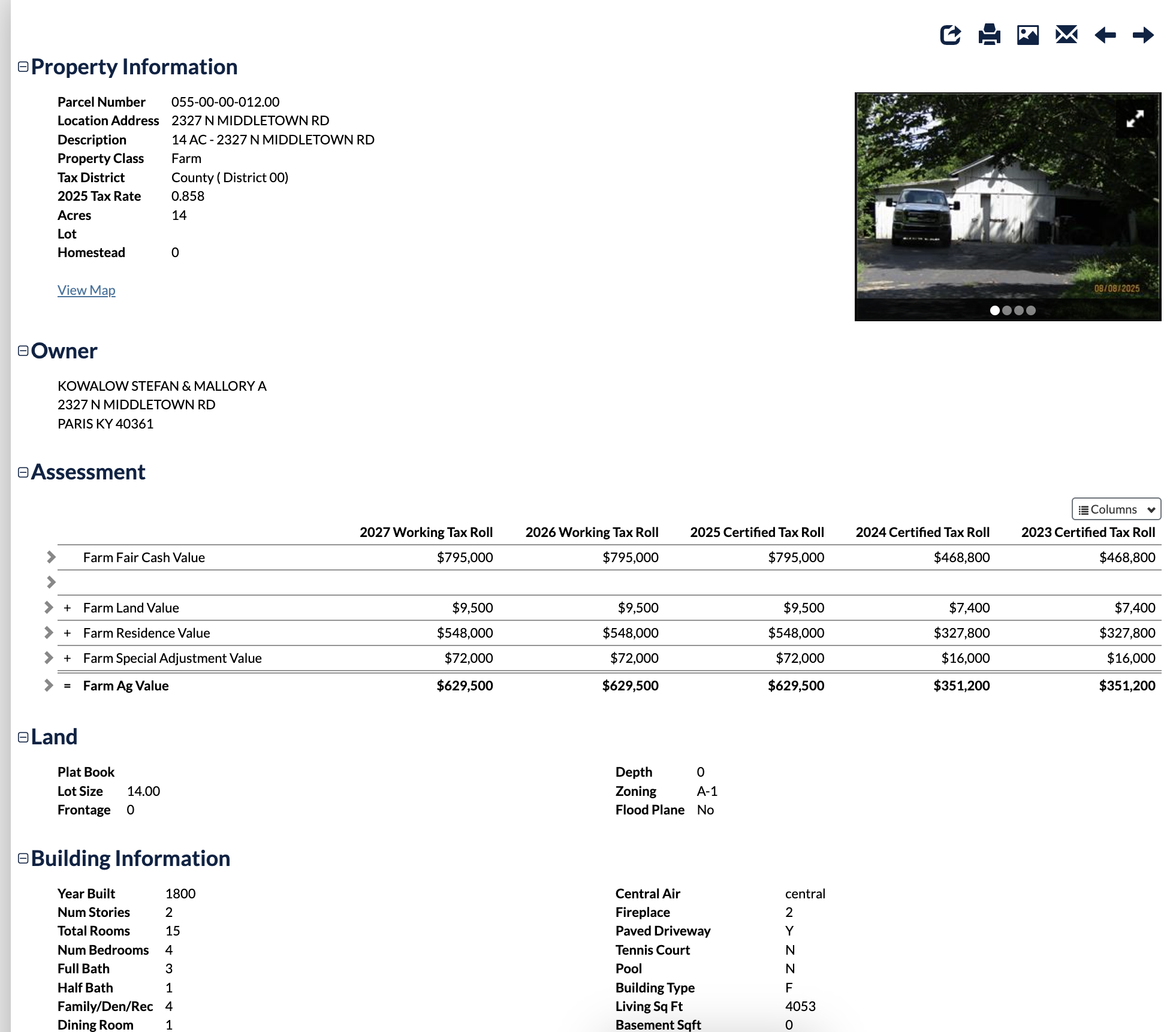
Our system was able to summarize the entire PVA card into a short, concise summary:
1800-built 2-story farm residence with 4053 sq ft living area, 4 bedrooms, 3 full and 1 half baths, 2 fireplaces, central heat/AC, and detached 3-car garage on 14 acres.
Further, we extract all the data into stuctured JSON which we store and use for ad-hoc queries
{
"summary": "1800-built 2-story farm residence with 4053 sq ft living area, 4 bedrooms, 3 full and 1 half baths, 2 fireplaces, central heat/AC, and detached 3-car garage on 14 acres.",
"parcel_number": "055-00-00-012.00",
"location_address": "2327 N MIDDLETOWN RD",
"description": "14 AC - 2327 N MIDDLETOWN RD",
"property_class": "Farm",
"tax_district": "County ( District 00)",
"tax_rate": 0.858,
"neighborhood": "",
"owner": {
"name": "KOWALOW STEFAN & MALLORY A",
"address": "2327 N MIDDLETOWN RD, PARIS KY 40361"
},
"valuation": {
"land_value": 9500,
"improvement_value": 548000,
"total_taxable_value": null,
"exemption_value": null,
"net_taxable_value": null,
"land_fair_cash_value": 9500,
"improvement_fair_cash_value": 620000,
"total_fair_cash_value": 795000
},
"land_info": {
"condition": "",
"plat_book_page": "",
"subdivision": "",
"lot": "",
"block": "",
"acres": 14,
"lot_sq_ft": null,
"shape": "",
"topography": "",
"utilities": {
"electric": null,
"water": null,
"gas": null,
"sewer": null
}
},
"improvements": [
{
"building_number": "",
"description": "",
"residence_type": "F",
"year_built": 1800,
"effective_age": null,
"structure": "",
"stories": 2,
"exterior": "ALU/VIN",
"foundation": "BRICK/STONE",
"construction_type": "",
"construction_quality": "",
"condition": "",
"roof_type": "",
"roof_cover": "",
"basement": {
"finish": "NONE",
"size": 0,
"type": "NONE"
},
"garage_type": "DETACH",
"garage_sq_ft": null,
"pool": "N",
"bedrooms": 4,
"full_baths": 3,
"half_baths": 1,
"total_rooms": 15,
"above_grade_sq_ft": null,
"total_finished_sq_ft": 4053,
"fireplaces": 2,
"heating": "HPMP",
"heat_source": "",
"heat_type": "",
"ac": "central",
"ac_type": "",
"special_improvements": "",
"porch_deck": "",
"porch_sq_ft": null
}
],
"sales": [
{
"sale_date": "2024-09-27",
"amount": 795000,
"buyer": "KOWALOW STEFAN & MALLORY A",
"seller": "MAZZETTI ALFONSO & LAURA C",
"note": "Z - Arms-Length Transactions"
}
],
"has_mobile_home": false,
"has_residence": true,
"has_building": true
}
Better decisions followed from better coverage: when every record contributes full structured data instead of a thin slice, patterns across counties and property types become visible earlier.
Approach
We kept the architecture practical: batch-oriented processing for throughput, clear error handling so failed records never disappear, and human-in-the-loop review for edge cases the models couldn’t confidently resolve. The focus was reliability at scale—not a demo that works on ten documents but breaks on ten thousand.
For a team already committed to examining thousands of PVA records annually, the win was not “do less work” but do the same scope with far more signal—faster collection, complete extraction, and summaries that make the extra data usable day to day.